Carrying on from our first post following the results of our developers’ adventures in the most recent ContrOCC hackday, here is the final set of projects:
- Client Provisions – Julian
- Alternative storage – Maciej
- WiX – Matthew
- DB upgrades with F# – Nathan
- Generating test data – Nigel
- New documentation – Steph
- Automating deployment – Tom G
- Automating component testing – Tom L
- Web-based CSV editor – Tomasz A
- Parsing & Analysing T-SQL – Trevor
Julian – Client Provisions
As anybody who has ever peeked under the bonnet of the Charging Engine will know, charges are based on Client Provisions. These are entirely derived from Care Package Line Items and there is a many to many relationship between the two. However, at many Local Authorities, Client Provisions have a one to one relationship with its corresponding Care Package Line Item in about 90% of cases.
To see whether there are any fundamental problems with imposing “1 CPLI = 1 CP = 1 CPLI”, I doctored code to only make one CP per CPLI and then ran the standard charging tests. This resulted in some errors being reported; those where the totals still agreed but were made up of different individual charges (i.e. correct) and those where the totals were different (incorrect). These will be reviewed soon.
Maciej – Alternative storage
The aim for my Hack Tuesday was to investigate alternative options for database storage especially for bulky but simple stuff like documents or audit data to improve some support related activities, like:
- Backup and restore performance
- Backup download time for purposes of investigation
The following options have been considered:
- Split databases (i.e. a master database and auxiliary database for the purpose of blobs/audit storage)
- Multiple file groups
- FILESTREAM option
It turned out that none of the above really matches our needs. Having separated databases possess a risk of internal consistency loss; multiple file groups are really tempting (in fact these are being exploited by some customers already), but these suit slightly different purposes; the FILESTREAM option may improve performance of some blob-related objects queries, but it does not provide any additional benefit in terms of backup/restore activities.
I have found some clues pointing out that we could exploit the read-only file groups to store audit data (or, to be exact, to move the audit data from the current to the archive table on some regular basis), which may allow for reduced locking, and some improved performance and faster backups (as there is no need to backup read-only file groups frequently; although that would require a different backup strategy).
Matthew – WiX
This time I ported one of our installers from Windows Installer Projects (which is deprecated) to Windows Installer XML (WiX). I chose the ‘Product Package Installer’ installer.
WiX is MSBuild based and declarative, requiring you to explicitly list all files that are installed. However, a built in tool (Heat) can be used to auto create fragments that list the files in a directory (it runs as a Pre-Build Target to the WiXProj).

You can optionally apply an XSL to exclude certain files, such a PDBs, that you don’t want installed. This could also be achieved with Pre-Build copies but the XSL transform is much more reliable.

The main ‘Product.wxs’ does the hard work, in the screeenshot below the Component Groups ‘Binaries’ and ‘Tags’ are WiX Fragments that were automatically created by Heat. Unfortunately, in order to have a Start Menu shortcut it is necessary to explicitly include the main executable file rather than letting Heat do the work, this is why ProductPackageInstaller.exe isn’t part of the ‘Binaries’ Component Group and is excluded from that Fragment by the XSL.

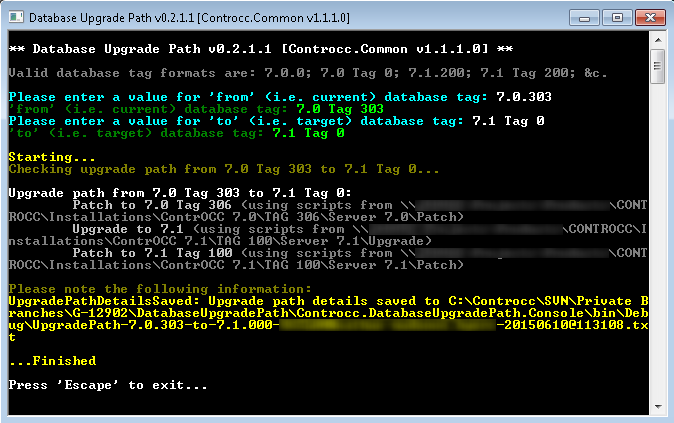
Nathan – DB upgrades with F#
I set about replacing the ‘What is the Upgrade Path’ wiki page, which describes how to upgrade a ContrOCC database from one version to another, with a standalone console application. The console application is written in F#: partly because it’s a good language for rapid prototyping and partly because I’m keen to gain more experience with the language – but primarily because I’d already collated the required structured branch / release / merge information as part of my ongoing development of the stress testing tool (also written in F#). The implementation is nearly complete: just some loose ends to tidy up, plus I’d like to add some unit tests.
Nigel – Generating test data
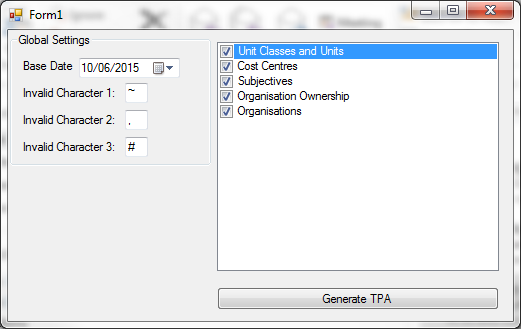
I attempted to create an application that would allow for TPA (our internal testing language) to be created just by ticking the types of data that you want in your database. The idea being that different combinations of data could be created without needing to hand code any TPA. I built a framework that sticks TPA together and only references TPA data if it exists (i.e. For Organisations the Organisation Ownership field is only populated if the Organisation Ownerships have been created.)
I also included a base date with a view to allowing the TPA to be generated for different dates but I did not find time to implement this feature. I did implement the feature of allowing a user to choose what “invalid” characters should be included in the test data. (i.e. for a CSV export file you want to include commas in your test data to make sure that the export can handle commas.) With the framework in place more TPA “bricks” can be added to the “TPA bricks” folder to extend what test data can be generated. As you can see from the screenshot below I have only implemented 5 test data items.
Steph – New documentation
Not having a particularly good long term memory, I have a habit of writing down any point of interest on completion of a task in my lab book. Notes can vary from where a particular feature lives the graphical user interface and how to use it, to schema diagrams or more specific development related reminders. As time has gone on, the earlier notes seem very obvious and I rarely refer to them personally, but on more than one occasion they have proved useful to a colleague and have been borrowed and even photocopied.
Since a lack of documentation is a common complaint amongst newer members of the team, I used hack day to start writing them up in a digital format which can be indexed and searched. This will be made available in a central location and hopefully added to over time.
Tom G – Automating deployment
I looked into trying to take some of the pain out of setting up the Remote Module for testing: with mixed results.
I ended up spending most of the day automating the tedious process of manually setting up the folders and scripts required for the module, which differs depending on whether you are doing an install or upgrade, as well as the version of ContrOCC you are testing. I ended up with a working C# command line application that fully automates this section of the process, albeit with a couple of limitations.
I also spent some time trying to programmatically hack IIS settings, but didn’t get too far. This is probably not worth the effort anyway as the changes we make in IIS for the Remote Synchronisation Service are quick and trivial. I was going to try modifying web.config files in C#, but I didn’t get around to this and again this is probably not worth the effort considering how minor the changes we make are.
Tom L – Automating component testing
I spent my hackday firstly trying to get my “C# component test runner” up and running on the latest branch. This tool is intended to build our C# solutions (all of them, for test purposes) and run our Visual Studio tests. Ideally once working this would be kicked off nightly. After banging my head against annoying MSBuild-from-the-command-line issues in the morning I made progress on actually running some tests in the afternoon, finally resulting in the ImportExport tests being run.
I have yet to see whether the results I’ve got from running the tests in debug mode against a WIP database bear any relation to the official results being seen by people running the tests the standard manual way.
Tomasz A – Web-based CSV editor
I tried recreating our reference data csv editor tool as web application to see if it’s feasible at all. I used MVC 5 + WebApi 2.0 + AngularJS + Bootstrap to create a single page application that could fetch, edit and update our reference information. Adding additional filtering to ease the navigation proved to be easy and effective though I ran out of time to implement actual updating of data in the database so at this point it’s just a fancy data viewer. With the potential to style quickly it could become quite useful and suit developer personal preferences. With the filtering it’s also much simpler to add/edit data required.
Trevor – Parsing & Analysing T-SQL
I wanted to look at ways of parsing T-SQL. Third party tools for T-SQL seemed pretty ropey. The general consensus on the message boards was to use the C# ScriptDom (Microsoft.SqlServer.TransactSql.ScriptDom).
Having established this as the correct approach, I started writing a simple win32 app that allows a SQL script to be specified, and the SQL parser is then used to inspect the script and report errors. The parser uses the “Visitor” code pattern to collect SQL fragments which correspond to scenarios that need to be examined. These fragments can then be broken down by casting them to specific DOM object types, providing helpful properties which prevent the need to write complex regex code to isolate SQL elements.
However the behaviour of the parser is complex, reflecting the complexity of T-SQL syntax (especially when inspecting JOIN fragments). While I managed to code a few scenarios (e.g. missing collate statements on temporary table definitions and missing decimal column precision declarations), I ran out of time when looking at some of the more complex scenarios.
My conclusion is that the functionality does show promise for writing more elegant tooling, however it requires significantly more time than hack day allows to fully explore this. I will therefore keep this project on hold, and hopefully revisit this on the next hack day.