Our ContrOCC hackdays give our developers a day to work on tweaks, gripes, improvements, or whole new features of their choosing and then sharing those with the rest of the team.
We have plenty of projects to talk about again this year so I have split this post in two; we’ll post the remaining projects soon. Here is the first set:
- Code analysis – Adam and Tomasz B
- Database schema documentation via metadata – Alan
- Upgrade AllTheThings to .NET 4.5 – Chris G
- XML import/export definitions – Chris H
- Loading lists asynchronously – Chris P
- Visualise database schema metadata – Damian and Pawel
- CSV column alignment tool – Ian L
- Generating database test scripts from UI interactions – Jon
Adam and Tomasz B – Code analysis
We did some research on Visual Studio’s Code Analysis tool. The tool automatically checks all code for compliance with a customizable set of predefined rules. Those rules check for common programming mistakes, adherence to good design practices, etc. There’s a wide selection of Microsoft recommended rules already built into Visual Studio, which can be cherry-picked to form custom rulesets.
We focused our work on developing a few custom rules that would enforce some of the ContrOCC specific conventions, such as using correct prefixes for variable names or making sure all forms inherit from the right base form. We’ve been able to develop a few sample rules and run them against the ContrOCC desktop client code as a proof of concept.
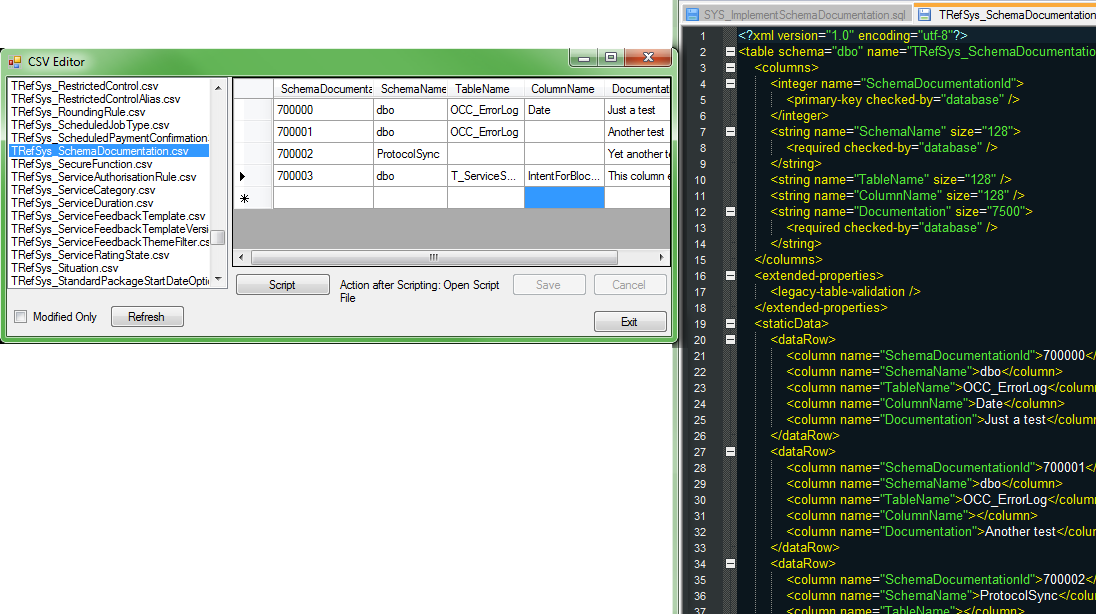
Alan – Database schema documentation via metadata
I put together a small demonstration of adding extended properties to database schema objects (specifically, schema, tables or columns) so that we can add documentation to them which can then be viewed in Management Studio. This is something I’d done in a previous hack day, but this time I put together ContrOCC-style infrastructure to support it, giving a rough idea of how I’d expected it to be done if we wanted to use this for real.
I also mocked up a representation of how the data in our system reference tables could be moved into the metadata file, rather than its current location in CSV files. This would mean we could ditch the CSV files for good, thus having one fewer place to find data. It would also mean not having to maintain the CSV column headers to keep them in line with schema changes, and the metadata representation of each table’s schema would be visible in the same file as the data.
Hopefully the data would also diff more easily in this form, and would be more human-readable when viewing diffs or editing files manually. If we were to implement this, the Data Maintenance Tool would be updated to read from and write to the metadata file rather than the CSVs – so, editing the data would be no different from before, but behind the scenes it would be stored in a more sensible way.
Chris G – Upgrade AllTheThings to .NET 4.5
Upgrade AllTheThings™ to .NET 4.5. Then try to find a cool, user facing, reason to keep it.
The first part of my task seemed trivial, the latter less so. Microsoft has fallen out of love with WinForms in favour of WPF, so there was little in the way of eye candy to entice users to higher versions of .NET (unless you count EnableWindowsFormsHighDpiAutoResizing in .NET 4.5.2). So I turned my attention to making the UI a bit more “U” friendly.
My efforts concentrated on my annoyance with having to support screen resolutions you can draw with a crayon. I looked into screens for creating new entities flowing through (a bit like a wizard) so we don’t need to present so many controls on one form. I also made the navigation bar collapsible to free up some real estate, this even works with the new hot-keys for keyboard navigation.
Chris H – XML import/export definitions
Our current representation of imports & exports uses a system of four interlinked system reference (TRefSys) tables. This means that the reference data defining any single export is scattered across four CSV files and has to be tied together with IDs. I’m interested in replacing this with a single XML file defining each import or export. This would have the following advantages:
- All data defining a single export is in one file so easier to comprehend
- XML is more human readable than CSV
- No need to manually type lots of IDs for sub items
For hack day, I focused on:
- Generation of XML from our existing TRefSys tables using SQL Server’s surprisingly helpful SELECT FOR XML feature. This would be used in the one-off transition to the new functionality.
- Writing temporary table functions which exactly reproduced the original contents of the TRefSys tables (including for now the IDs) this then enabled existing code to be updated to use the XML via these functions with a simple search & replace operation.
- Conversion of one actuals import to XML format
This was a success, and I was able to get the relevant import test to pass with the TRefSys definition of the same import deleted. The next step (which I didn’t have time for) would be to eliminate the unwanted Database IDs from the format and rewrite the SQL which depends on them.
Chris P – Loading lists asynchronously
For hack day I have produced a working prototype which performs asynchronous population of lists which should reduce delays users experience with populating lists as while the overall time is unchanged the application becomes responsive quicker. This also means if filter conditions are entered which lead to a long delay then the filter conditions can be immediately modified.
Changes made:
- Return to UI immediately list population started
- While SQL running:
- Show “Loading…” in list (instead of normal SQL wait dialog)
- Disable list so no editing allowed
- Populate list on completion of SQL
- Kill executing SQL if no longer required:
- Move to different content type (i.e. control disposed)
- Filter conditions change (i.e. another call to mFillList)
Other ideas:
- It might make sense to modify lazy loading so in background start loading one list at a time anyway. Need to ensure loading for displayed lists are shown immediately
- We might want to limit maximum number of SQL commands which can execute at a time: probably only really an issue for accounts screen where we have a lot of tabs
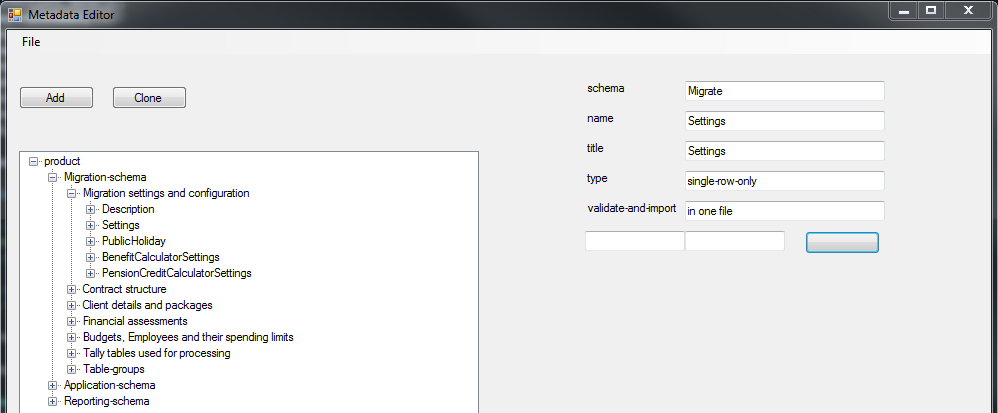
Damian and Pawel – Visualise database schema metadata
Aim: To help maintain metadata files when creating/editing new database tables, columns etc.
What we did:
- Visualise ContrOCC Metadata.xml file in more readable form (TreeView)
- Edit existing attributes (most of them)
- Add new attributes
- Add new instances of the nodes
Near the end we realized that the problem is harder and more complex than we thought. There is still a lot of work to do, but it was a fun challenge!
Ian L – CSV column alignment tool
I chose to create a file pre-processor that formats a CSV file such that all the columns line up and a post-processor which removes all the padding added by the pre-processor.
These file processors could then be used by AraxisMerge, the file difference tool I use, to help make comparing our table CSV files from the Data directory easier to compare.
As an extra challenge, I used PowerShell to write the file processors.
Learning how to use PowerShell took more time that I expected and the Cmd Applets that I thought existed did not, which means I will have to write more script than I anticipated.
Jon – Generating database test scripts from UI interactions
My task was to explore providing a user-friendly UI for generating database test scripts from the ContrOCC UI. I spent most of the day getting to grips with the ContrOCC UI Framework which I’ve never had to do any serious work with before, so it was a great training day for me though not very productive.
I reached the point of being able to open a form from the Troubleshooting menu which contained lists of clients and cplis with tick-boxes for selection. Unfortunately before I committed Visual Studio crashed and scribbled all over my main .cs file so I have no screenshot or code. However, now I know what I’m doing it should be fairly quick to repair if I ever return to this.