Carrying on from our first post following the results of our developers’ adventures in the most recent ContrOCC hackday, here is the final set of projects:
- Graphically presenting performance information to the lay developer – Julian Fletcher
- Cleaning up the developer documentation – Maciej Luszczynski
- CSV Merger – Matthew Clarke
- F#/C# – Nathan-Madonna Byers
- ContrOCC version manager – Nigel Palmer
- An executable imports/exports specification – Patrick Donkor
- Improving code integrity checks – Steph Sharp
- Migration from within the ContrOCC UI – Tom Litt
- Taming our test scripts – Tomasz Agurciewicz
- SQL Server projects in VS2012 – Trevor Hingley
Julian Fletcher – Graphically presenting performance information to the lay developer
We are now amassing ever greater amounts of anonymous performance information from live Local Authority (LA) databases:
- execution times
- deadlocks
- missing index hints.
This information is transferred, via CSV files, from all the LA databases to a shared OCC server. Here, several Stored Procedures may be used to analyse the figures. However, these output slightly impenetrable tables, so I set about presenting the information in a graphical format using SQL Server Reporting Services (SSRS).
Setting this up was fairly tedious – in particular, getting all the necessary permissions (even when everything was on my own machine). However, in summary, this is how it works:
- You set up a SQL Server to have SSRS. This results in a couple of new databases being created:

- Configure SSRS using the Configuration Manager:
- Install the Microsoft SQL Server Report Builder application and design your reports. These can obtain their data from a database on an entirely different server.
- Save them to your hard drive and then publish them the Report Server when they’re ready.
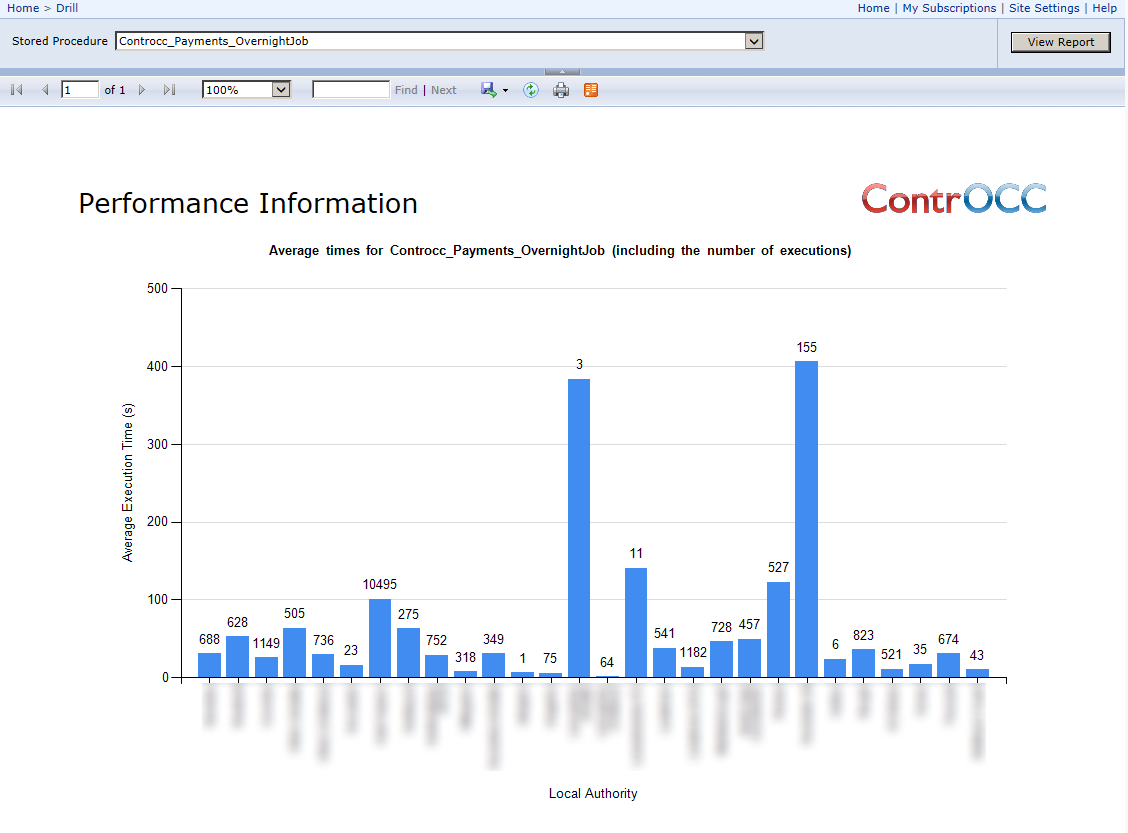
- The screenshot shows what this looks like. You can get the averages at all LAs for any one stored procedure:
- You can also drill through to get a by-version breakdown for a particular LA (not down – this is a slightly different concept):
- Just by chance, I’ve chosen a stored procedure which appears to have sped up in later versions!


As I mentioned above, getting the right permissions was a pain and I still haven’t made the Report Server available to other users but I hope to be able to soon.
Maciej Luszczynski – Cleaning up the developer documentation
I focused on providing How To documentation for new developers on the wiki. I started by cleaning up existing pages. The Home page is now greatly improved, although the Windows Topics section still requires clean-up.
I have also identified some topics that it might be useful to add to the wiki, such as:
- how to remove a database object
- how to remove a database table properly
- how to commit a change to the SVN properly
- how to check the imports flow
Matthew Clarke – CSV Merger
This tool improves merging of CSV data files which often cause SVN conflicts, for example when a column is added.
The tool can be set to be your default merge tool for CSVs in SVN.
When you would normally resolve conflicts CSVMerger now opens.
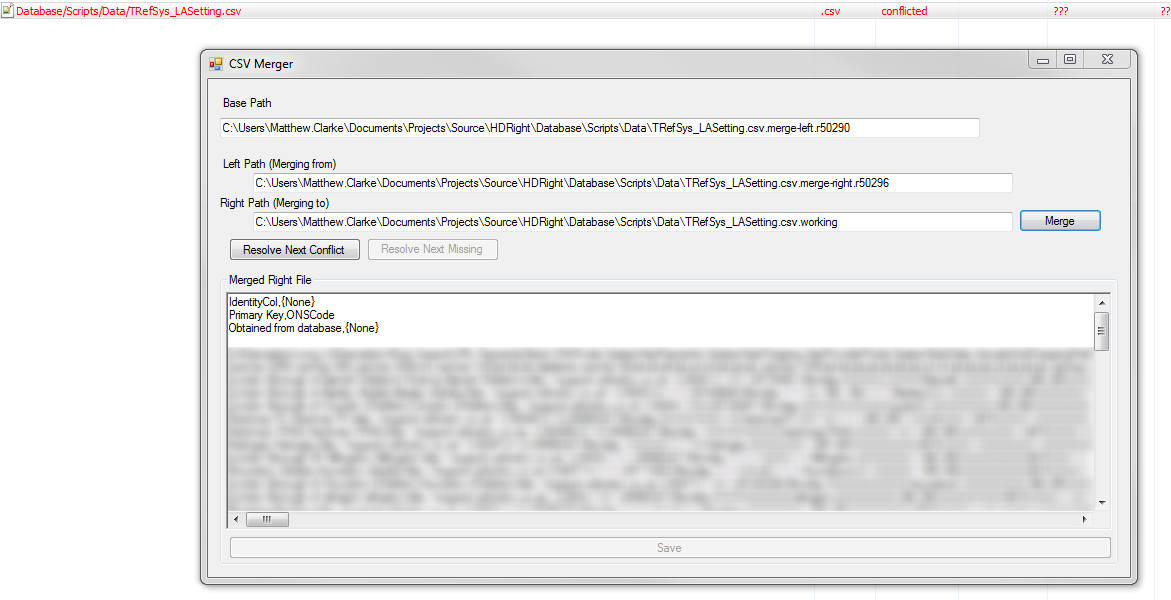
It will highlight conflicts and missing values for new columns:
You can even resolve conflicts via the UI (needs polish).
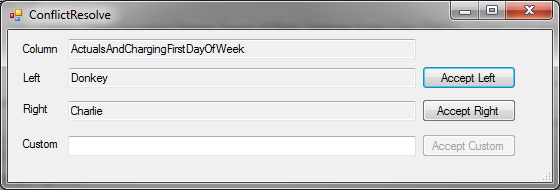
So, you’ll be able to go home 5 hours early because the merge was done in no time.
Nathan-Madonna Byers – F#/C#
I looked at using various F# Type Providers (from the open-source FSharp.Data.SqlClient package) to interact with ContrOCC databases in a type-safe manner, such that many errors can be caught at compile-time rather than raising run-time exceptions. In particular, I investigated the potential of this approach for writing test data scripts and worked through the implications of exposing this functionality to C# code.
The first thing to note is that there’s little in my prototype that couldn’t have been achieved solely in C#. However, I find F# to be a more natural and expressive language for this kind of thing. In terms of F#/C# interoperability, there were a few head-scratching issues that took a while to figure out – but it all seems to work pretty smoothly. (Famous last words.)
A quick summary of the specific Type Providers:
- SqlProgrammabilityProvider: This can be used when working with stored procedures. Unfortunately, it doesn’t currently support SPs with output parameters or explicit return values, which rules out many of our SPs.
- SqlCommandProvider: This can be used when working with arbitrary SQL commands. I’ve used this in my prototype as a lightweight wrapper around SPs (e.g. rather than calling an
_InsertSP directly, I can have a simple three-line SQL command: declare an@IDparameter; execute the SP [passing@IDas the output parameter]; select the@ID). - SqlEnumProvider: This can be used to create enumerations for (relatively) static lookup data, e.g. from
TRefSys_tables. This means that it may no longer be necessary to define these enumerations manually in our C# code (and then have to worry about keeping them synchronized with the database &c.).
In terms of extending the prototype, various factors – the use of the SqlCommandProvider and the succinctness of F# (plus type inference and auto-generics) – mean that the amount of hand-written “boilerplate” code required is fairly small. (It’s not dissimilar to the amount of hand-written SQL needed to do it the old way but should be quicker to write.) The thing that really takes time is the need to analyze the SPs in relation to the database schema, e.g. to decide: which parameters to expose to C#; which should be mandatory, etc.
Finally, a summary of the key benefits:
- Static typing (and Type Provider “magic”) mean that many errors can be caught at compile-time.
- Intellisense (including visibility of defaults for optional parameters) and auto-completion.
- Optional parameters are truly optional: no more “counting commas”!
- The scripts are (more) readable.
- Debugging support and full stack traces for exceptions.
- “Production” SPs – i.e. those used by the UI (and other components) – are always used.
- Modularization, i.e. we can finally share portions of data setup across tests.
Nigel Palmer – ContrOCC version manager
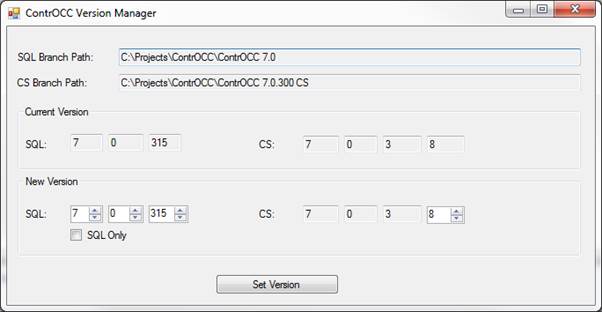
I set out to create a version number manager to assist with the building of ContrOCC. Version numbers are currently set manually in a variety of different places and there is some risk of one of them being missed. This tool will allow the developer responsible for the build to set all version numbers in the SQL database and the C# code. This will improve the accuracy of the build process and prevent test failures due to incorrect version numbers.
The ContrOCC Version Manager tool has a simple user interface that allows the user to set the version number. This then updates all the required build files to have the new version number.
Patrick Donkor – An executable imports/exports specification
I spent my Hack Day looking at how I could use Specflow as a way of creating an executable specification for the development of new Imports/Exports.
The idea is take a specification using the Gherkin syntax to specify a top level view of an import/export. This specification would be agreed upon between an IM and the Client. The specification would be passed to the developer who would code and test against it.
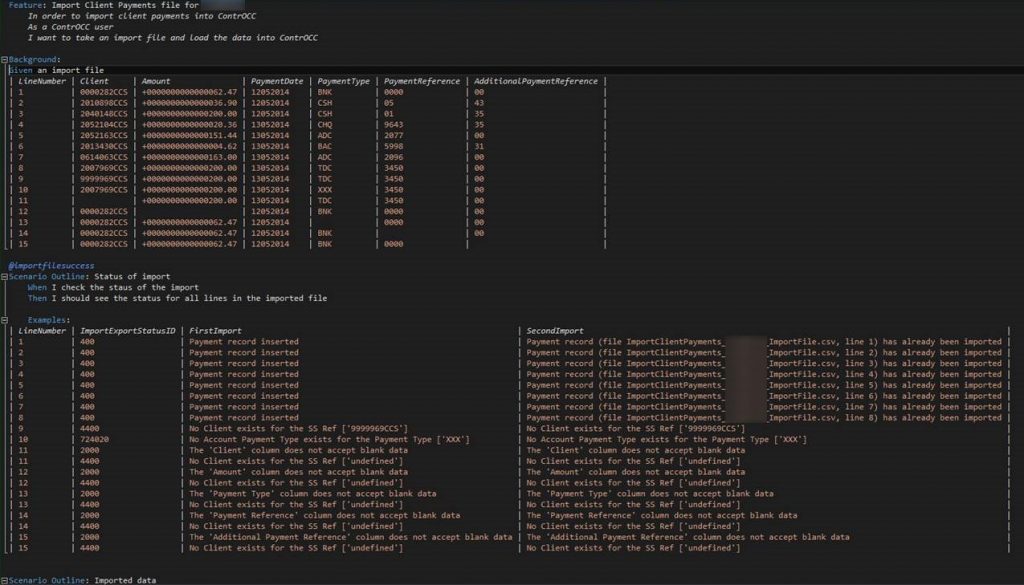
To see if this could be done, I used an existing client payments import as my template. I spent the first part of the day setting up the specification for the import. This went well. The second half of the day was spent trying to implement automated tests to use against the specification. I did encounter a few minor issues that, given time, could be rectified. The screenshot below shows what a sample file looks like.
Steph Sharp – Improving code integrity checks
I spent the day trying to suppress output from one of our internal code integrity checks (sys_checkschema). This output is an unwanted side effect, and can be confusing, especially to newer members of the team. Although I did manage to prevent this output being displayed, I was unsuccessful as there were problems with expected errors no longer being reported and the addition of spurious new errors, which I was unable to resolve.
Tom Litt – Migration from within the ContrOCC UI
I took the brief “make the migration process at new customer sites a part of the ContrOCC UI” and tried to see whether it would be feasible to run migrations via a wizard available in the main desktop client, instead of the existing process where there is a separate tool. Why? If a customer had this, they wouldn’t have to send data off-site. They could re-run migration tables as often as they liked. Selling this to us, we could ditch the SQL Server Integration Services packages which are a merge nightmare.
In production the wizard, would:
- allow editing of migration settings
- allow selection of files to be migrated in, or perhaps just point at a directory full of migration CSVs
- run through each file independently, or run them all in an unattended batch; depending on the level of reporting required
- feedback on the level of success/failure for each file.
The file specifications and import code are already written, so this is a case of wrapping the code as stored procedures and putting UI on it.
In practice I got as far as establishing a wizard, selecting the client file, importing it and writing the existing HTML feedback to the wizard. This could be extended fairly easily to handle all files and report more nicely, and I think this is worthy of future effort.
Tomasz Agurciewicz – Taming our test scripts
ContrOCC’s testing meta language takes some time for developers to learn. That’s why I decided to finish/enhance a tool I made some time ago which makes it easier:
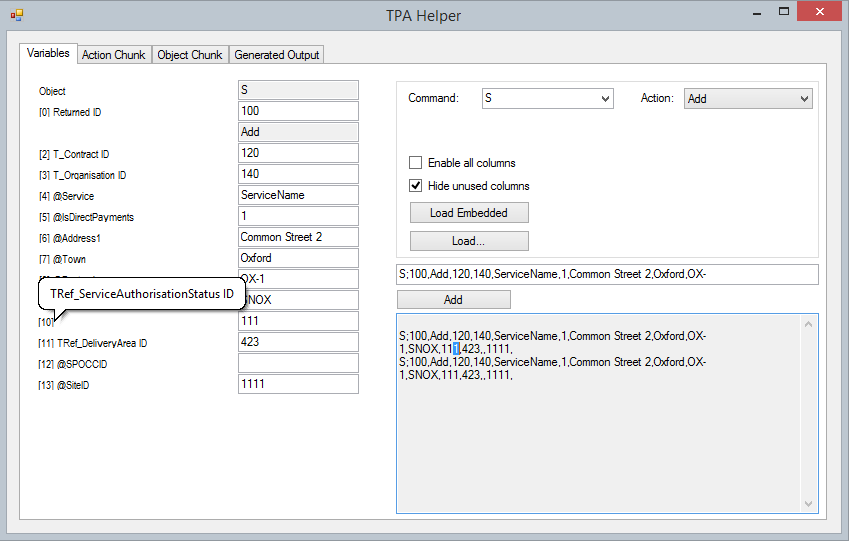
The tool parses a test script and tries to present its contents in a sane fashion. All commands are listed in the Command dropdown, and selecting one of them lists available actions. So for example Command “S” (Service) has actions “Add” and “Load”.
Next, for the selected action it finds the appropriate sql part in the script and tries to list what each column stands for. It then lets you enter all the required data and form a single test script line that you can use later on when preparing tests or data for ContrOCC. It also prints the selected chunk in a separate tab, so you can look up if in doubt what each parameter does.
Trevor Hingley – SQL Server projects in VS2012
I looked at SQL Server projects in Visual Studio 2012, with a view to seeing how viable it would be as a tool for ContrOCC database development and deployment.
There are immediate issues in that the SQL Server Data Tools (SSDT) installed on the machine must be in line with Visual Studio. In my case creating a project in VS2012 immediately raised an error, as the SSDT were not compatible.
After installing the latest version of SSDT, I found the SQL Server project very easy to use. Database schema can be imported from a database, a selection of scripts or a .dacpac file very easily. Multiple projects can be used to handle separate version schemas, and the tooling makes comparison between projects/schema easy to view and update. Pre- and post-deployment scripts can also easily be added to the project.
Where the viability of the SQL Server project type fails is in deployment. Schemas can easily be deployed to databases which can be connected to, and scripts can be generated to create a new database or upgrade from a known schema to the latest schema. However, there is no versioning capability when generating scripts to be able to produce scripts capable of upgrading from multiple schema versions to the current version. A possible alternative is to generate .dacpac files which have versioning capability. However this was not found to be viable, as a .dacpac generated in VS2012 causes an xml schema error when attempting to import into a 2k8 SQL Server database.